
생각을 즐기는 개발자, 윤병욱입니다.
깊은 고민과 행동이 문제를 해결한다고 믿습니다.
저는 문제 해결을 위해 생각하는 과정 자체를 즐기는 개발자입니다. 복잡한 시스템 속 병목을 분석하고, 시스템을 최적화해 실질적인 성능 개선을 이끌어낸 경험이 있습니다.
단순히 기능을 구현하는 것이 아닌, 프로젝트에서 어떤 문제가 있었고, 왜 그것을 해결해야 했는지, 시간과 비용을 이해하고 주도적으로 개선하는 데 집중해왔습니다.
Tech Stacks
Project: Resona
Resona: 글로벌 커뮤니케이션을 위한 실시간 SNS 플랫폼
실시간 커뮤니케이션의 언어·문화 장벽을 해결하기 위해 기획된 SNS 플랫폼
- 역할: 백엔드 전담 (API 서버, 채팅 서버, 클라우드 인프라, CI/CD)
- 기능:
- 회원가입, 로그인, 소셜 로그인(OAuth2) 기능
- 이메일 인증 및 임시 토큰 발급 기능
- Feed 작성, 조회, 수정, 삭제 기능 (이미지 포함), 댓글 및 대댓글 기능
- 이미지 파일 업로드 (Oracle Cloud Object Storage 연동)
- 커서 기반 페이지네이션 지원 (피드, 댓글 등)
- 관리자 전용 API 엔드포인트 분리 및 Role 기반 권한 제어
GitHub - API Server | Swagger | 기술 블로그
2024.03 ~ 진행 중 | App 1명 + BE 1명(본인)
문제 해결
📌 문제: 최대 응답 시간 59초
서버 부하 상황에서 Feed/Comment API의 최대 응답 시간이 59초에 달하며 사용자 경험 저하 및 타임아웃 발생
✅ 해결: ThreadPoolTaskExecutor 튜닝
core: 20 / max: 100 으로 비동기 스레드 풀을 조정하여 대량 요청에 안정적으로 대응할 수 있도록 개선
결과: Feed 최대 응답 시간 59초 → 1.4초, 오류율 0.02% → 0%
📌 문제: 조회 쿼리의 성능 저하
Offset 기반 페이지네이션 및 N+1 문제로 인한 DB 부하 및 느린 응답 속도
✅ 해결: 커서 기반 페이지네이션 + Fetch Join
createdAt 기반 커서와 인덱스 힌트 적용으로 N+1 문제를 제거하고 데이터 접근 성능을 향상시킴
결과: Feed 평균 응답 시간 3.25% 개선
📌 문제: 이미지 업로드 시간 지연
멀티 파일 업로드 처리 시간이 길어 사용자 대기 시간이 증가함
✅ 해결: 이중 버킷 업로드 + 병렬 업로드
Buffer → Disk 구조로 설계하고, parallelStream으로 병렬 업로드 처리하여 처리 시간 단축
결과: 이미지 업로드 시 병렬 처리로 속도 체감 개선 및 실패율 감소
Resona API Server Architecture
장기적인 서비스 운영을 고려해 인프라는 프리티어 기준에서 AWS 대비 비용 경쟁력이 높은 OCI로 구축했습니다. 또한, 사용자 증가로 인해 발생할 수 있는 보안 및 확장성 문제를 사전에 대비할 수 있도록 구조를 설계했습니다.
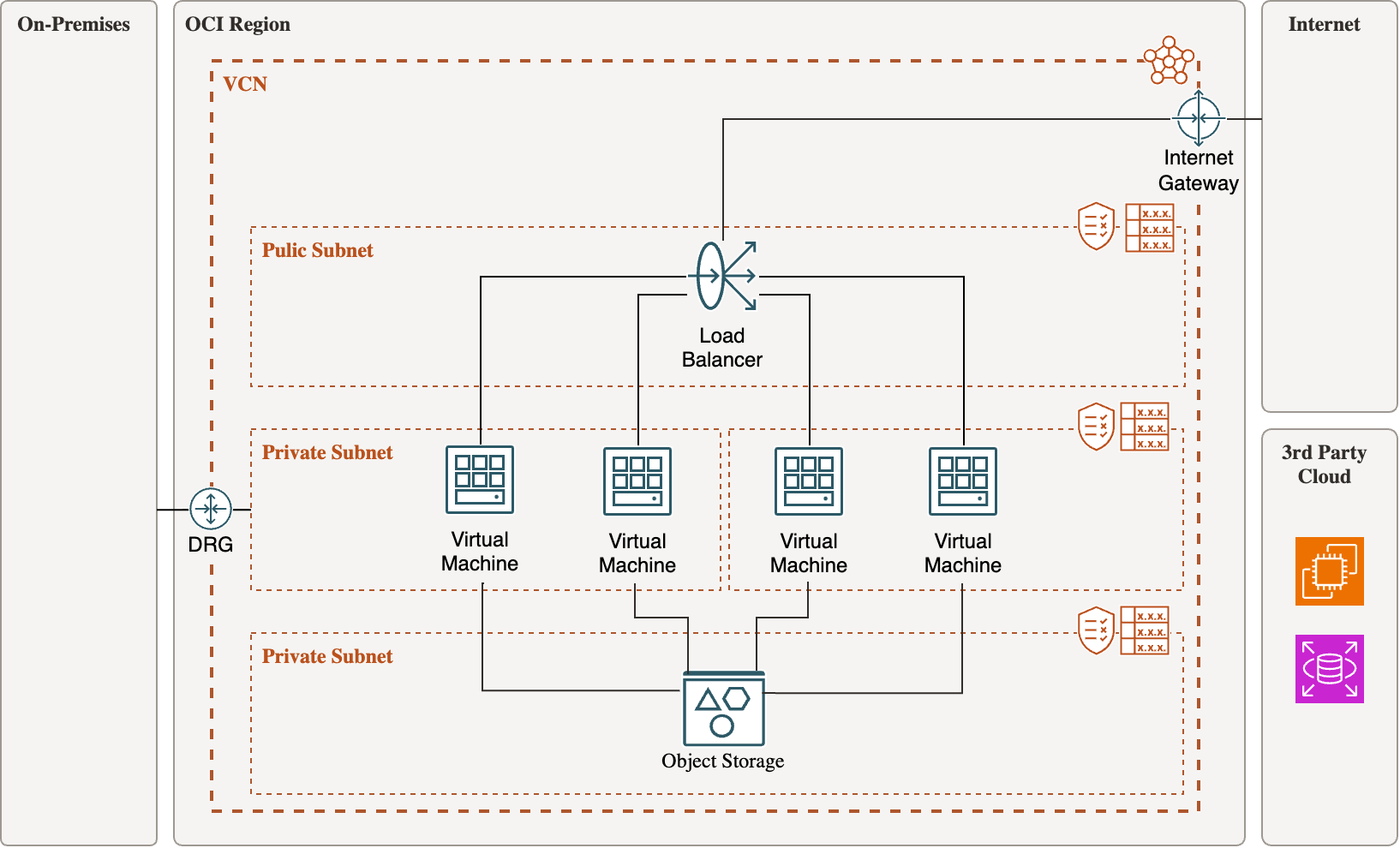
- Java(Spring Boot) 기반 SNS 서버 + Kotlin 기반 채팅 서버로 도메인 분리
- 모든 서버는 Private Subnet에 배치, Nginx만 Public Subnet에 노출
- OCI Bastion 서버를 통해 보안 유지한 채 유지보수 수행
Nginx가 현재는 reverse proxy 역할을 하며, 각 2개 이상의 API 서버와 채팅 서버에 같은 진입점을 제공합니다. 모든 서버는 private subnet에 배치하여 보안 이슈를 차단하고, CI/CD는 GitHub Actions와 Bastion 서버를 활용해 구성했습니다.
트래픽 증가에 따라 서버 인스턴스를 수평 확장하고, 로드 밸런서를 적용하여 안정적인 서비스 운영을 계획하고 있습니다.
Project Specification
Resona API 서버는 크게 멤버 및 멤버 정보 관리, 그리고 SNS 기능(피드, 댓글 등)을 기준으로 구성되었습니다.
본 프로젝트는 대용량 요청 상황에서도 안정적인 서비스를 제공하기 위해 다양한 성능 최적화 기법을 적용하였으며, 그 효과를 검증하기 위해 다음과 같은 부하 테스트 환경을 구성했습니다. 동시 사용자 수 100명~1,000명 단위 증가 및 Feed 데이터 100만~500만 건까지 단계적으로 부하를 가중시키는 테스트 환경에서 측정하였습니다.
성능 병목 지점 분석
부하 테스트 결과를 기반으로 주요 병목 구간을 시각화한 뒤, 각 계층별로 병목의 원인을 분석했습니다. 그 과정에서 총 5가지 정도의 병목 의심 지점을 도출했으며, 이 중 대표적인 3가지를 중심으로 설명하겠습니다.

CPU 사용률 급증
19:58~20:02, 20:04~20:08 구간에서 시스템 CPU 사용률이 최대 72%까지 급증했습니다. 응답 시간 또한 해당 구간에서 길어졌고, 부하 주기가 명확히 나뉘어 병목 지점으로 판단했습니다.

스레드 수 증가
추정 부하 시기에서 Thread 수가 40 → 70으로 급등했으며, GC나 요청 처리와 밀접한 연관이 있어 병목 지점으로 판단했습니다.

커넥션 생성 시간 병목
커넥션 풀 10개 설정에도 평균 생성 시간이 250ms를 초과했습니다. 트래픽 초반 동시 커넥션 급증으로 인한 병목으로 판단했습니다.
주요 개선 사항
- ThreadPoolTaskExecutor 커스터마이징 및 Tomcat/비동기 쓰레드 풀 조정으로 대용량 비동기 작업 안정화
- Feed 최대 응답 지연 문제 해결
- Comment 최대 응답 지연 문제 해결
- Feed 평균 응답 시간 3.25% 감소, 댓글 평균 응답 시간 3.6% 감소
- N+1 문제 해결을 위한 Fetch Join 및 cursor 기반 페이지네이션 적용
- 요청 처리량(req/s) 4.72% 증가, 오류율 0.02% → 0% 감소
- Oracle Object Storage 기반 이중 업로드 구조(Buffer → Disk) 및 병렬 업로드 구현
문제해결 과정
테스트 결과를 기반으로 시스템 리소스, 애플리케이션, 데이터베이스 계층별로 메트릭을 분석한 결과, 총 5가지의 병목 가능성이 있는 지점을 도출하였고 이 중 CPU 사용률 급증, 스레드 수 급등, DB 커넥션 생성 지연을 주요 병목 요인으로 선정하였습니다.
먼저, Feed 조회 및 댓글 조회와 같은 읽기 중심 요청에서 발생한 응답 지연을 해결하기 위해 여러 대안들을 검토했습니다. 대표적인 대안으로는 WebFlux 기반의 논블로킹 구조로 전환하거나, 메시지 큐(RabbitMQ, Kafka)를 도입하여 조회 요청 자체를 분산 처리하는 방식이 있었습니다. 하지만 이들 방식은 현재 Spring MVC 아키텍처에서 구조적인 변경이 필요하며, 구현 복잡도와 운영 부담이 크게 증가하는 단점이 있었습니다.
이에 따라 보다 현실적이고 적용 범위가 명확한 ThreadPoolTaskExecutor 커스터마이징과 Tomcat 비동기 쓰레드 풀 조정을 통해, 조회 요청 처리 시 발생하는 스레드 병목을 완화하고 응답 지연을 줄이는 방향으로 최적화를 진행하게 되었습니다.
또한, SNS 기능에서 N+1 문제로 인해 발생하는 데이터 접근 병목을 해결하기 위한 방안으로는 Redis 캐싱이나 ElasticSearch를 활용한 검색 전용 엔진 도입도 고려되었습니다. 이 방법들은 조회 성능을 극대화할 수 있지만, 데이터 정합성과 구조 변경에 따른 추가 유지보수 부담이 동반됩니다.
따라서 JPA 기반에서도 쉽게 적용 가능한 Fetch Join을 우선 적용하고, 페이지네이션 방식도 offset 기반에서 cursor 기반으로 전환하여 성능 효율을 극대화했습니다. 특히 createdAt 필드를 커서로 활용하고 @QueryHints를 통해 인덱스를 명시함으로써 쿼리 최적화도 진행하였습니다.
문제 해결 결과
이러한 최적화는 실제 부하 테스트 결과를 통해 정량적으로도 효과가 입증되었습니다. 피드 조회 API의 최대 응답 시간은 54.9s에서 1.3s로, 댓글 작성 API는 52.9s에서 1.4s로 대폭 감소하였습니다.
평균 응답 시간 역시 피드의 경우 284.57ms → 275.31ms, 댓글은 380.84ms → 367.19ms로 각각 3.25%, 3.6% 개선되었으며, 에러율은 0.02%에서 0%로 안정화되었습니다.
요청 처리량(req/s)도 약 4.72% 증가하였으며, 전체 시스템의 처리 성능이 전반적으로 향상되었습니다. 성능 측정은 k6 기반 테스트 환경에서 평균, 최대, 95퍼센타일 응답 시간과 CPU/메모리 사용률을 중심으로 진행되었습니다.
향후 계획
스레드 풀 최적화 전략 고도화
이번 부하 테스트를 통해 단순히 스레드 수를 늘리는 것만으로는 성능이 항상 향상되지 않는다는 점을 확인하였습니다. 특히 1 OCPU 환경에서 과도한 스레드 수는 오히려 컨텍스트 스위칭 비용 증가로 인해 성능을 저하시킬 수 있음을 경험했습니다.
이 과정에서 최적 스레드 수 = CPU 수 × (1 + (대기 시간 / 처리 시간))이라는 공식을 참고하게 되었고, 작업 성격에 따라 I/O 중심인지 CPU 중심인지 구분하여 스레드 수를 계산해야 한다는 점을 알게 되었습니다.
실측 기반 스레드 튜닝 적용
따라서 향후에는 실제 비동기 작업의 평균 처리 시간과 대기 시간을 기반으로 실측 값을 수집하고, APM이나 로그 분석을 통해 적정 스레드 풀 크기를 지속적으로 튜닝할 계획입니다.
Redis 기반 캐시 전략 도입
이번 테스트를 통해, 현재 인프라가 1 OCPU에 비해 6GB 메모리가 상대적으로 여유로운 구조라는 점에 주목하게 되었습니다. 이는 높은 연산 성능보다는 데이터 캐싱을 활용한 효율적인 처리 구조가 더 적합한 환경이라고 판단하였습니다.
정적/반복 조회 대상 캐싱 계획
이에 따라 자주 조회되는 정적 데이터나 반복 호출이 많은 API 응답에 대해서는 Redis 기반 캐싱을 적용할 계획입니다. 이는 CPU 부담을 줄이는 동시에, DB 커넥션 수와 평균 응답 시간을 동시에 개선할 수 있는 전략이라고 판단하였습니다. 피드 좋아요 수, 조회수, 카테고리 목록, 외부 API 응답 등은 Redis에 캐싱하여 요청 시 빠르게 응답하고, @Cacheable을 활용한 Spring Cache 추상화를 통해 TTL 설정과 자동 만료 정책도 함께 적용할 예정입니다.
Redis 기반의 비동기 처리 개선
향후에는 비동기 작업 중에도 Redis를 통해 처리 여부를 판단하거나 결과를 재활용하는 방식으로, 단일 코어 환경에서의 처리 효율을 더욱 끌어올릴 계획입니다. 이를 통해 CPU 리소스의 낭비를 방지하고, 전체 시스템이 더 많은 요청을 효율적으로 처리할 수 있는 구조로 발전시킬 수 있지 않을까 생각하고 있습니다.
Feed 도메인 구조 개선을 위한 CQRS 도입
현재 Feed 도메인은 JPA 기반의 관계형 모델 위에서 운영되고 있으며, 복잡한 연관관계 및 다양한 조회 조건으로 인해 구조적 한계와 성능 이슈가 점차 드러나고 있습니다.
Feed, Image, Comment, Like, Member 간의 다중 연관관계를 포함한 복합 쿼리는 N+1 문제뿐만 아니라 쿼리 복잡도 증가, 조회 속도 저하, 유지보수 난이도 상승 등의 문제를 야기하고 있습니다. 특히 커서 기반 페이징, 좋아요 수 포함, 댓글/이미지 포함 여부 등 다양한 조회 조건이 동시에 요구되면서 기존 RDB 기반 구조로는 유연한 대응이 어렵다고 판단하였습니다.
이에 따라, CQRS 아키텍처를 도입하여 조회 책임을 MongoDB로 분리하는 방안을 고려하게 되었습니다. 쓰기/수정/삭제는 현재 구조(MySQL + JPA)를 그대로 유지하고, 조회는 MongoDB 기반의 FeedReadModel Document를 통해 처리함으로써 조회 성능과 구조의 단순화를 동시에 달성하는 것이 목표입니다.
다른 기능 개선
이미지 업로드 처리 개선
이미지 업로드 기능의 경우 Presigned URL을 활용한 클라이언트 직접 업로드 방식도 고려하였으나, 서버 측에서의 검증과 메타데이터 추출, 후처리 필요성이 높았습니다.
이에 따라 Oracle Object Storage의 Buffer → Disk 구조를 적용하고, parallelStream()을 활용한 병렬 업로드 방식으로 서버단 처리와 사용자 경험을 동시에 개선하였습니다.
Awards
Community
개발 커뮤니티에서 다양한 방식으로 기술 공유 및 협업을 실천하고 있습니다.



